
We describe here the implementation of Mandelbrot fractal image generation using Hybridizer. The language of choice is C#, and implementation is done using 32-bits precision arithmetic.
Mandelbrot set is the set of values c for which the sequence:
z_0 = 0\\
z_{n+1}= z_n^2 + c
\end{array}\right.\)
remains bounded in the complex plane.
It happens an equivalent definition is:
That means that while calculating \(z_n\) values exceeds \(2\) at any iteration, the point c is not in the set.
C# implementation
In other words, this can be simulated via this code:
public static int IterCount(float cx, float cy)
{
int result = 0;
float x = 0.0f;
float y = 0.0f;
float xx = 0.0f, yy = 0.0f;
while (xx + yy <= 4.0f && result < maxiter) // are we out of control disk?
{
xx = x * x;
yy = y * y;
float xtmp = xx - yy + cx;
y = 2.0f * x * y + cy; // computes z^2 + c
x = xtmp;
result++;
}
return result;
}
which has to be run for every point (cx, cy) in the complex plane.
To produce an output image, we therefore compute IterCount for every pixel in the square \([-2,2]\times[-2,2]\), discretized as a \(N\times N\) square grid:
public static void Run(int[] light)
{
for (int i = 0; i < N; i += 1)
{
for (int j = 0; j < N; j += 1)
{
float x = fromX + i * h;
float y = fromY + j * h;
light[i* N + j] = IterCount(x, y);
}
}
}
where N, h, fromX and fromY are application parameters.
We here compute a \(2048\times 2048\) image using C# on a core i7-4770S @ 3.10GHz.
This unoptimized versions runs in 420 milliseconds, yielding
Its crystal clear that this code is embarrassingly parallel, since all pixels are independant from each other.
A first trivial optimization would therefore to make the first loop parallel:
public static void Run(int[] light)
{
Parallel.For(0, N, (i) => {
for (int j = 0; j < N; j += 1)
{
float x = fromX + i * h;
float y = fromY + j * h;
light[i * N + j] = IterCount(x, y);
}
});
}
This second version runs in 67 milliseconds, giving:
Run on the GPU
In order to run that on a GPU, we just need to decorate the Run method with EntryPointAttribute:
[EntryPoint("run")]
public static void Run(int[] light)
{
Parallel.For(0, N, (i) => {
for (int j = 0; j < N; j += 1)
{
float x = fromX + i * h;
float y = fromY + j * h;
light[i * N + j] = IterCount(x, y);
}
});
}
and some boilerplate code to invoke the generated method:
HybRunner runner = HybRunner.Cuda("Mandelbrot_CUDA.dll").SetDistrib(N, 128);
wrapper = runner.Wrap(new Program());
wrapper.Run(light_cuda);
This modified code runs on the GPU (a 1080 Ti) in 10.6 milliseconds (32 when counting the memory copies), giving:
Further optimization
Launching a block per image line is highly suboptimal, due to the unevenly distribute nature of the computations. For example, threads at the square’s border will immediately converge, while those on the set will take the longest runtime.
This can be seen by profiling the above code using Nsight:
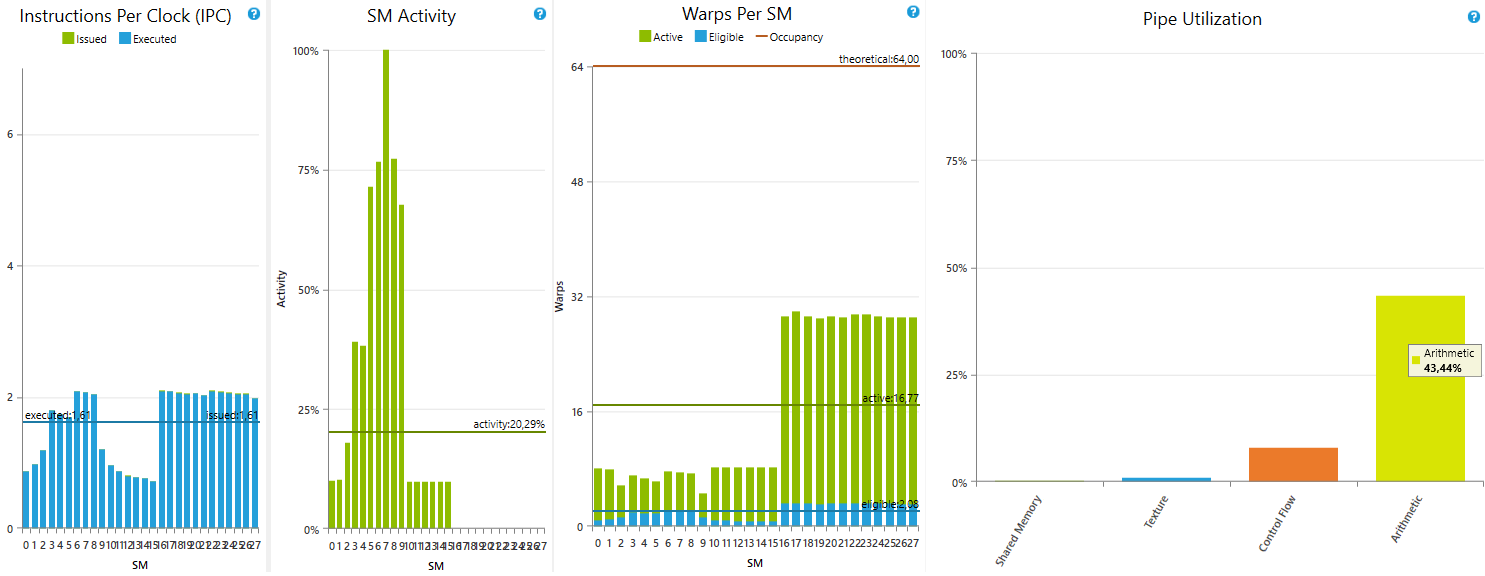 As we can see, half of multiprocessors are idle.
As we can see, half of multiprocessors are idle.
We can instead distribute the work more evenly by using a 2D grid of relatively small blocks.
Fortunately, Hybridizer supports CUDA-like parallelism, so we can modify our entrypoint this way:
[EntryPoint("run")]
public static void Run(int[] light)
{
for (int i = threadIdx.y + blockDim.y * blockIdx.y; i < N; i += blockDim.x * gridDim.x)
{
for (int j = threadIdx.x + blockDim.x * blockIdx.x; j < N; j += blockDim.y * gridDim.y)
{
float x = fromX + i * h;
float y = fromY + j * h;
light[i * N + j] = IterCount(x, y);
}
}
}
and run it with a 2D grid:
HybRunner runner = HybRunner.Cuda("Mandelbrot_CUDA.dll").SetDistrib(32, 32, 16, 16, 1, 0);
The modified code runs now in 920 microseconds on the GPU, meaning:
If we profile the newly generated kernel, we get:
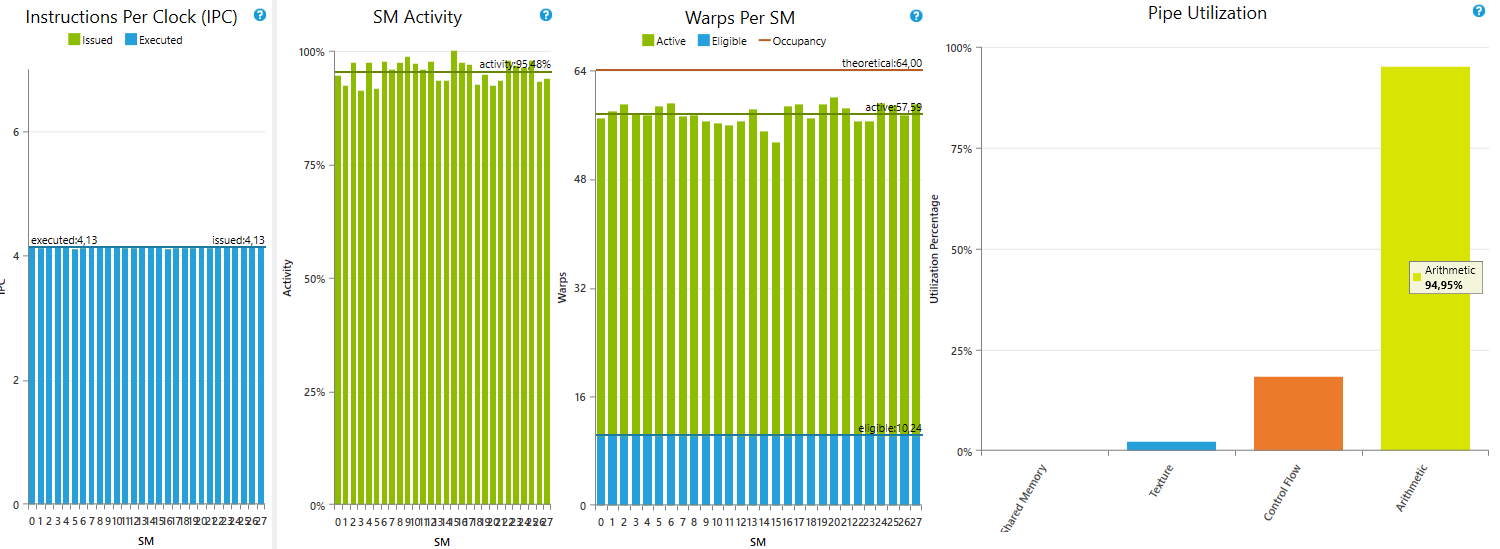
main stall reason being “Other” with 69% followed by instruction fetch for only 5% of not eligible warps.
It’s reasonable to not try further optimization.
Conclusion
In this post we presented a basic usage of hybridizer, from unoptimal c# to highly efficient generated cuda code. We started by optimize our c# code and the migrated it seamlessly to CUDA.
We then optimized our c# code for CUDA GPUs, until we reached a close to peak performance level.