
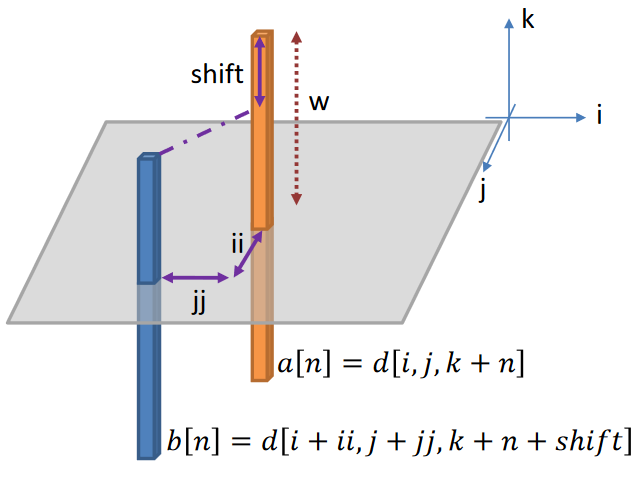
A wide variety of image processing algorithms are typically parallel. However, depending on filter-size or neighborhood search pattern, memory access is critical for performances. We’ll show how loop reordering and memory locality fine-tuning help achieve best performance. Using Hybridizer to automate Java byte-code transformation to CUDA source code, and using new CUDA feature Run Time […]
Tags: CUDA, Image Processing, Java